An Introduction to Text Analytics
Text analytics, sometimes alternately referred to as text data mining or text mining, refers to the process of deriving high-quality information from text. High-quality information is typically derived through the devising of patterns and trends through means such as statistical pattern learning. Text mining usually involves the process of structuring the input text, deriving patterns within the structured data, and finally evaluation and interpretation of the output. Typical text mining tasks include text categorization, text clustering, concept / entity extraction, production of granular taxonomies, sentiment analysis, document summarization and entity relation modeling (i.e., learning relations between named entities). The overarching goal is, essentially, to turn text into data for analysis via application of natural language processing (NLP) and analytical methods. A typical application is to scan a set of documents written in a natural language and either model the document set for predictive classification purposes or populate a database or search index with the information extracted. [From Wikipedia]

Simply put, given a set of textual data, text mining helps answer the questions "who, what, where, when and how". This helps answer the question "why" as well as what can be done to impact future outcomes if required.
Text analytics has a come a long way since first attempts at it were made in the 1970s and 1980s. In the 1970s and early 1980s, text analytics started with Bag of Words extraction. For example, consider the following sentence:
Cstmr not happy with his bank account - Customer wants to switch to Yes Bank.
Text analytics tools would extract the following words:
Cstmr
Customer
Yes
Bank
happy
not
switch
bank
account
From this we are able to gather that the sentence relates to a bank account customer but not much else. The technology then improved in the 1980s where Bag of Words extraction gave way to Expressions Extraction. We were able to gather that the same sentence now contained the following expressions:
Cstmr
Customer
Yes
Bank
not happy
switch
bank account
As you will appreciate, the expression "not happy" conveys a very different meaning than the word "happy"! With the 1990s, came another breakthrough in text analytics with the ability to extract Named Entities. This helped identify what was being discussed as can be seen below:
customer --> CRM term
Yes Bank --> Bank (not the affirmative)
From Named Entities Extraction, we have now moved to possibly the most important breakthrough in text analytics, that of Sentiment Analysis. Sentiment Analysis helps us identify subjective information in textual data. We are now able gather the following information:
Customer (cstmr) --> bank account --> unhappy (Negative)
Switch to (negative) --> Yes Bank (competition)
As is apparent, tremendous strides have been made in the technology to extract information from unstructured text data. We now also have the ability to convert unstructured data into structured fields so they can be used in predictive analytics and structured data mining.
So what are the main categories of information that a sophisticated text mining application can extract from unstructured text data? These are as follows:
- Named Entities Extraction
- Document Summarization
- Theme Extraction
- Concept Extraction
- Sentiment Analysis
Let us discuss each of these categories in detail below.
1) Named Entities Extraction
Named Entities Extraction helps answer the question "who, what and where" is being discussed. Let us take the following paragraphs from a recent Reuters news article as an example:
(Reuters) - Research In Motion Ltd said on Tuesday its subscriber base has risen to 80 million from the 78 million it reported earlier this year, surprising many on Wall Street and sending its shares up more than 3 percent.
Most analysts had expected RIM, for the first time in its history, to begin losing subscribers in the recently completed quarter as it has rapidly lost market share in North America to Apple's snazzier iPhone and Samsung's Galaxy devices.
The Named Entity Extraction process would yield the following results:
Note that the software is sophisticated enough to identify Apple as a company and not a fruit and Galaxy and a product and not an astronomical term.
2) Document Summarization
Document summarization is the creation of a shortened version of a text by a computer program. The product of this procedure still contains the most important points of the original text. Once again, let us take the two paragraphs from Reuters as an example:
(Reuters) - Research In Motion Ltd said on Tuesday its subscriber base has risen to 80 million from the 78 million it reported earlier this year, surprising many on Wall Street and sending its shares up more than 3 percent.
Most analysts had expected RIM, for the first time in its history, to begin losing subscribers in the recently completed quarter as it has rapidly lost market share in North America to Apple's snazzier iPhone and Samsung's Galaxy devices.
A summary of these paragraphs is as follows:
Research In Motion subscriber base has risen to 80 million sending its shares up more than 3 percent. Most analysts had expected RIM, for the first time in its history, to begin losing subscribers.
As can be seen, the summary captures the gist of the conversation. While this may not be impressive in the case of a two paragraph article, the ability to rapidly summarize large volumes of text data is a very useful output from sophisticated text mining applications.
3) Theme Extraction
Theme Extraction answers the question "what are the important words being used"? Once again, if we take our example sentences from Reuters, we see the following themes being discussed:
(Reuters) - Research In Motion Ltd said on Tuesday its subscriber base has risen to 80 million from the 78 million it reported earlier this year, surprising many on Wall Street and sending its shares up more than 3 percent.
Most analysts had expected RIM, for the first time in its history, to begin losing subscribers in the recently completed quarter as it has rapidly lost market share in North America to Apple's snazzier iPhone and Samsung's Galaxy devices.
The main themes being discussed here are:
- Subscriber base
- Shares
- Market share
4) Concept Extraction
Concept extraction or concept mining is an activity that results in the extraction of concepts from artifacts. Because artifacts are typically a loosely structured sequence of words and other symbols (rather than concepts), the problem is nontrivial, but it can provide powerful insights into the meaning, provenance and similarity of documents. The mappings of words to concepts are often ambiguous. Typically each word in a given language will relate to several possible concepts. Humans use context to disambiguate the various meanings of a given piece of text, where available [Source: Wikipedia].
Concept Extraction answers the question: "what" are the important high level concepts?
Once again, taking our Reuters example, we see the following concepts being discussed:
(Reuters) - Research In Motion Ltd said on Tuesday its subscriber base has risen to 80 million from the 78 million it reported earlier this year, surprising many on Wall Street and sending its shares up more than 3 percent.
Most analysts had expected RIM, for the first time in its history, to begin losing subscribers in the recently completed quarter as it has rapidly lost market share in North America to Apple's snazzier iPhone and Samsung's Galaxy devices.
The main concepts being discussed here are:
- Technology
- Business
- Smart phones
5) Sentiment Analysis
Sentiment analysis or opinion mining refers to the application of natural language processing, computational linguistics, and text analytics to identify and extract subjective information in source materials. Generally speaking, sentiment analysis aims to determine the attitude of a speaker or a writer with respect to some topic or the overall contextual polarity of a document. The attitude may be his or her judgment or evaluation, affective state (that is to say, the emotional state of the author when writing), or the intended emotional communication (that is to say, the emotional effect the author wishes to have on the reader) [Source: Wikipedia].
Sentiment analysis answers the question: is what being said "positive" or "negative"?
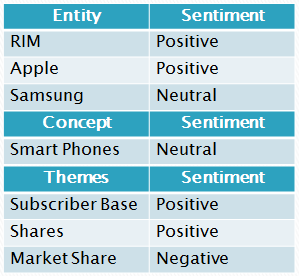
A sophisticated text analytics tool can identify the sentiments associated with the named entities, concepts as well as themes being discussed in the text data. Examining our example once again, we note the following sentiments associated with named entities, concepts and themes:
(Reuters) - Research In Motion Ltd said on Tuesday its subscriber base has risen to 80 million from the 78 million it reported earlier this year, surprising many on Wall Street and sending its shares up more than 3 percent.
Most analysts had expected RIM, for the first time in its history, to begin losing subscribers in the recently completed quarter as it has rapidly lost market share in North America to Apple's snazzier iPhone and Samsung's Galaxy devices.
Conclusion
From the above discussion, we can see that by extracting the named entities, themes, concepts and sentiments from textual data, one can quickly understand who / what is being discussed, in relation to what, where, how and when. This helps one figure out why something is happening (the shares of RIM are going up because they added subscribers) and what must need to do in future to drive towards a desired outcome.



Very nice article, I used some of your useful concepts to write my own article: Self-Service Business Intelligence and Natural Language Reporting. I'd love to get your feedback. Don't you think that Natural Language Business Intelligence is the next step of Business Intelligence's evolution?
ReplyDeleteTim, my apologies for the delayed response. Nice article. I haven't had the opportunity to view the Qwalytics demo yet but I generally agree that NLP will play a major role in analytics as the focus on unstructured data increases. Take a look at IBM's Neo project - that may of interest to you as well.
Delete