SPSS Deployment: Collaboration & Deployment Services
SPSS Deployment is all about "operational-izing" the predictive models developed using SPSS Modeler. Broadly, this includes Collaboration & Deployment Services (C&DS) and Decision Management (DM). In today's blog, we will focus on C&DS.
C&DS provides a secure foundation for analytics. It provides the technology infrastructure to manage analytic assets (predictive models), share them securely throughout the enterprise and automate processes. This enables an organization to make better decisions consistently.
There are three aspects to C&DS:
1) Collaborate - C&DS makes it possible to share and re-use assets efficiently, protect them in ways that meet internal and external compliance requirements and publish results so that a greater number of business users can view and interact with results.

2) Automate - Automation enables the organization to make analytics a core component of the daily decision-making processes. You can construct flexible analytical processes that can be operationalized, ensuring consistent results. You also have the tools you need to govern analytical environments just as you manage other business processes.

3) Deploy - Deployment bridges the gap between analytics and action by enabling organizations to operationalize analytics – embedding analytic results in front-line business processes. Linkage between C&DS and other IBM SPSS products like DM supports the automation of recommendations and tactical decisions.
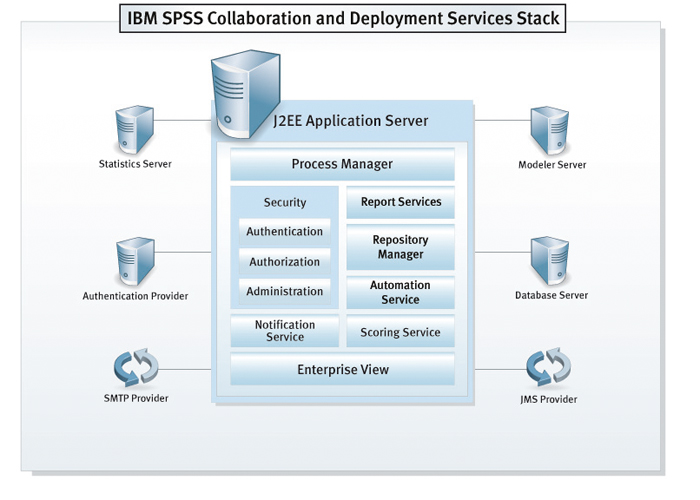
In summary, with C&DS you can:
- Leverage shared knowledge;
- Support consistent decision making; and
- Deploy flexible, repeatable processes.
(Source: IBM.com)



Thanks for informable post.
ReplyDeleteThank you.
DeleteThanks for sharing. ViS optimizes medical product development by enabling access to a complete map of global clinical research infrastructure.
ReplyDelete